Ein Forschungsbericht aus den Google Labs zur Entwicklung eines spezifisch für Tutoring trainierten grossen Sprachmodells. Die Ergebnisse zeigen eine Überlegenheit eines auf Finetuning basierenden Modells gegenüber spezifischen Prompting-Strategien. Es bleiben aber Fragen offen.
– – –
Kontext
Wir explorieren bei SCIL Academy seit einiger Zeit Möglichkeiten, CustomGPTs für verschiedene Szenarien im Bereich selbstorganisiertes und selbstgesteuertes Lernen zu nutzen. Also beispielsweise
- virtuelle Lernbuddies, mit denen man überprüfen kann, ob man sich ausreichend intensiv mit dem Skript zu einem Modul auseiander gesetzt hat;
- virutelle Tutoren, die einen bei der Erarbeitung von Wissensthemen unterstützen;
- virtuelle Rollenspielpartner, mit denen man kleine Rollenspiele und Simulationen durchführen kann.
Die Prompts, die wir dafür entwickeln, sind teilweise sehr detailliert und können bis zu 8’000 Zeichen (knapp 4 Seiten) an Anweisungen umfassen.
In einem aktuellen Bericht argumentiert eine Forschungsgruppe bei Google, dass dies letztlich nicht der richtige Weg sei. Vielmehr bräuchte es auf Tutoring spezialisierte LLMs, die durch einen finetuning-Prozess angepasst wurden. Das hat mich natürlich neugierig gemacht…
– – –
LearnLM-Tutor – und der Weg zu “pädagogischen” LLMs
Der Bericht der Forschungsgruppe ist umfangreich (86 Seiten) und teilweise recht technisch. Die Entwicklungsarbeiten waren Teil eines Google-weiten internen Projekts mit Beteiligung von Personen aus Projekten wie Google DeepMind, Google Research, Google LearnX usw. Darüber hinaus waren Wissenschaftler verschiedener Hochschulen (Arizona State University, Lund University, Oxford University) eingebunden.
Die übergeordnete Zielsetzung der Projektarbeit war nicht so sehr die Entwicklung eines “pädagogischen” LLM, sondern vielmehr das Erkunden von Wegen, wie künftige Versionen des LLM Gemini dahin gebracht werden können, dass sie auch als wirksame pädagogische Agenten genutzt werden können. (11)
Die Begründung der Forschungsgruppe, warum sie bei ihren Arbeiten auf finetuning an Stelle von Prompting gesetzt haben, lautet wie folgt:
Out of the box, gen AI models have a remarkable ability to understand user queries expressed in
natural language and generate responses that synthesise relevant information from across the internet
(used in the gen AI pre-training) to answer in a helpful and harmless way. However, by default, these
models do not typically behave like human tutors. Such default behaviour can be modified in two ways: prompting or fine-tuning (through supervised and/or reinforcement learning). (…) Prompting is the easiest and most popular way to adjust the behaviour of gen AI.
(…)
The prompting approach, however, has a number of limitations. Most importantly, it requires explicit specification of what good tutoring behaviours look like in natural language. This involves enumerating what should be done and when, what should be avoided and when, all the possible exceptions to the rules, etc. This makes prompted gen AI-based tutors similar to ITSs: while gen AI is more general and faster to build (based on an existing foundation model), in the end both are limited by declarative knowledge of what the best educational practices look like. (…) However, we found that most pedagogy is too nuanced to be explained with prompting. Furthermore, prompting produced unreliable and inconsistent results, because there are limits to how much it can push the behaviour of gen AI away from the core principles ingrained into it during the pre-training and instruction tuning phases of its development.
(…)
While far less computationally intensive than the standard pre-training phase, fine-tuning can still be costly to perform on models with many billions of parameters (…), which explains why it is less explored in the gen AI for education literature compared to prompting. However, fine-tuning (RL in particular) may enable AI to capture some of the intuition and reasoning that humans use in effective teaching, leveraging backpropagation to search the vast space of pedagogical possibilities.
Für die Entwicklung des LearnLM-Tutor-Modells auf der Basis von Gemini 1.0 wurden zunächst Datensätze (menschliche & synthetische) erzeugt. Die Ausführungen hierzu sind im Bericht vergleichsweise kurz. Diese Datensätze wurden dann für das Finetuning des Modells verwendet. In einem nächsten Schritt wurden dann ein Vorgehen für die Evaluation und ein Bewertungsschema entwickelt.
Evaluationsergebnisse
Für die Evaluation haben Lernende (Novizen und Expert:innen) umfangreiche Lerndialoge mit dem LearnLM-Tutor-Modell geführt (ca. 45 Minuten). Inhaltlich basierten diese auf YouTube Videos mit Aufzeichnungen zu Lehrveranstaltungen aus Informatik, Biologie, Chemie, Literaturwissenschaft, Geschichtswissenschaft und anderen Disziplinen. (17; 59)
Die verschiedenen, im Verlauf der Evaluation von LearnLM-Tutor eingesetzten Tests und die daraus resultierenden Ergebnisse zeigen, dass LearnLM-Tutor (finetuning) in den meisten Aspekten dem Basismodell Gemini 1.0 (mit spezifischem Prompting für Tutoring) überlegen ist. (25) Dies betrifft beispielsweise Aspekte wie die folgenden:
- Als wie freundlich wurde der virtuelle Tutor erlebt?
- Wie stark fördert der virtuelle Tutor das Engagement im Lerndialog?
- Wie gross war der subjektiv wahrgenommene Lernerfolg?
Die folgenden Grafiken zeigen Vergleichsergebnisse, die auf automatisierten Evaluationsverfahren basieren:

(Bildquelle: Jurenka et al. 2024, S. 17-19)
Neben den automatisierten Vergleichstests wurden in einem weiteren Evaluationsstrang Bewertungen von weiteren Personen (Generalisten sowie Pädagogik-Expert:innen) eingebunden, die die Tutoring-Dialoge zwischen Studierenden und LearnLM-Tutor analysierten. Die folgende Tabelle liefert eine Übersicht zu drei der vier Evaluationsverfahren, den verwendeten Bewertungskriterien und den erzielten Ergebnissen:
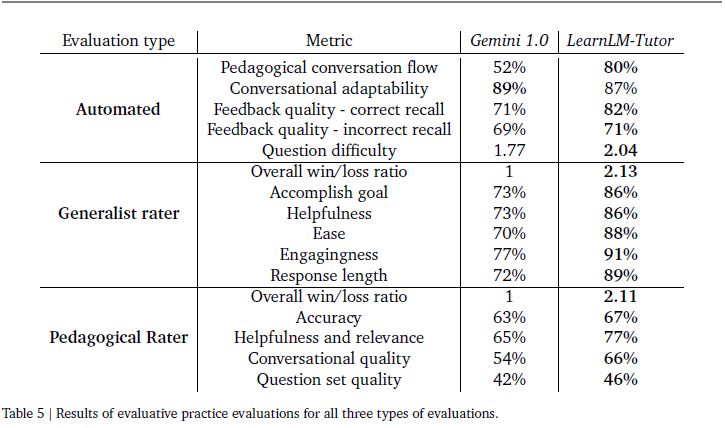
Risiken
Die Forscher:innen bzw. Entwickler:innen haben sich auch mit möglichen Risiken des Einsatzes von GenKI im Tutoring-Prozess befasst. Dabei haben sie u.a. die folgenden Aspekte berücksichtigt:
The families of risks we studied and planned mitigations for included bad model outputs, such as hallucinations, toxicity, biased outputs, and bias in the teaching level; changes in the learner’s behaviour, such as loss of autonomy, persuasion and emotional dependency; and privacy and surveillance, such as the collection of sensitive data and inferring and monitoring of emotions.
Für den Aspekt “praise for harm-inducing queries” (also wertschätzende Behandlung durch das Tutor-Modell von Fragen zu potenziell gefährlichen Handlungen) wird eine quantitative Auswertung geliefert. Dabei zeigt sich, dass mit jeder Modellversion der Anteil der unpassenden Reaktionen (“failure”) deutlich reduziert werden konnte (aber eben auch nicht ausgeschlossen).

Offene Fragen
Nach der Lektüre des Berichts bleiben bei mir noch offene Fragen zurück:
- Auf Basis von genau welchem Modell wurde die Studie durchgeführt?
- Aus dem Bericht geht (für mich) nicht klar hervor, mit welcher Version von Gemini 1.0 gearbeitet wurde. Gemini 1.0 ist in drei Versionen (Nano, Pro, Ultra) mit jeweils unterschiedlicher Leistungsfähigkeit verfügbar (Gemini Team 2023). An einer einzigen Stelle im Bericht findet sich eine Erwähnung von Gemini Pro (13).
- Sind für das Finetuning ausreichend spezifische Operationalisierungen von “gutem Tutoring” verwendet worden? Die Autor:innen verweisen hierzu an zwei Stellen auf entsprechende Operationalisierungen. Zum einen auf allgemeine Tutoring-Strategien wie z.B. die folgenden:
– Do not just give away the answers. Instead, help the learner discover their own answers. Then help them take their next steps.
– Aim to return appropriate credible resources.
– Be a safe space to make mistakes.
Zum anderen auf Strategien bzw. Prinzipien, die insbesondere für KI-Tutoren wichtig sind. Dazu gehören etwa die folgenden:
– Stay on topic of tutoring and learning, and the particular subject being tutored.
– Be relevant and receptive.
– Do not repeat yourself verbatim.
– Do not claim to be embodied or human.
- Reizt das zum Vergleich verwendete Tutor-Prompt von Mollick / Mollick (2023; mehr zu diesem Prompt hier) die Möglichkeiten für spezifisches Prompting aus? Bei diesem handelt es sich zwar um einen umfangreichen Prompt. Ich gehe aber davon aus, dass es möglich ist, deutlich spezifischere und leistungsfähigere Tutoring-Prompts zu entwickeln.
- Gilt die hier aufgezeigte Überlegenheit eines mit Finetuning für Tutoring angepassten Sprachmodells auch für andere Typen von LLMs, also beispielsweise OpenAIs GPT-4?
Wenn es hierzu Stimmen aus der GenKI-Community bzw. von Spezialist:innen für Tutoring gibt, bin ich sehr daran interessiert, diese zu hören.
– – –
Eckpunkte zu LearnLM-Tutor
- Basis:
Gemini 1.0 mit finetuning für “gutes” Tutoring. - Trainingsdaten:
“We curated a collection of diverse pedagogical datasets, consisting of multi-turn conversations, for the purpose of supervised fine-tuning. These datasets include human-authored multi-turn pedagogical dialogues as well as synthetic data produced by larger models. We mix these datasets in varying proportions based on their quality to optimise training outcomes. Additionally, we curated specialised single-turn datasets specifically designed to mitigate deficiencies in model behaviour.”
(Jurenka et al. 2024, S. 54) - Input & Output:
Text - Einsatzszenarien:
“LearnLM-Tutor is trained for text-based AI tutoring grounded in high-quality lesson materials.”
(Jurenka et al. 2024, S. 54)
– – –
Verweise
Gemini Team (2023). Gemini: A family of highly capable multimodal models. Arxiv.org
Jurenka, I., Kunesch, M., & McKee, K. e. a. (2024, May 14). Towards responsible development of generative AI for education: An evaluation-driven approach. googleapis.com.
Mollick, E., & Mollick, L. (2023). Assigning AI: Seven Approaches for Students, with Prompts. SSRN.