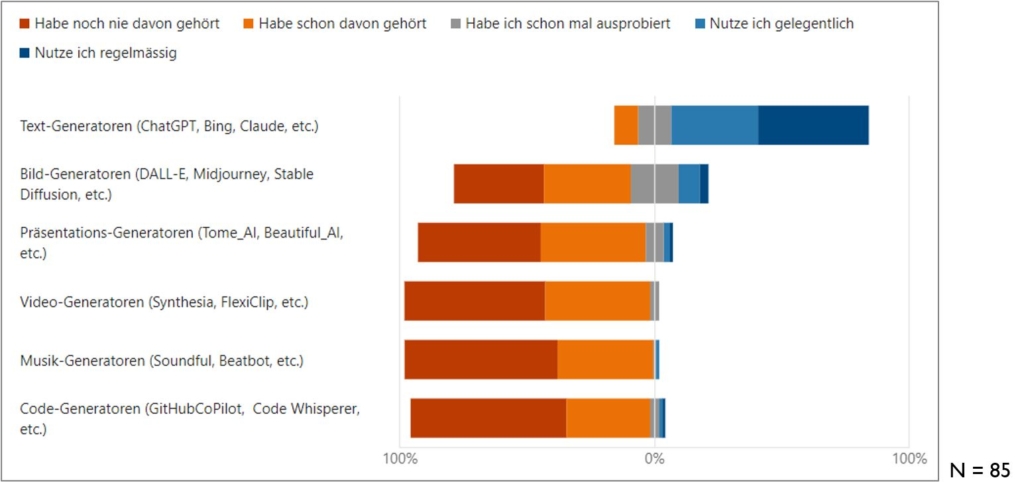
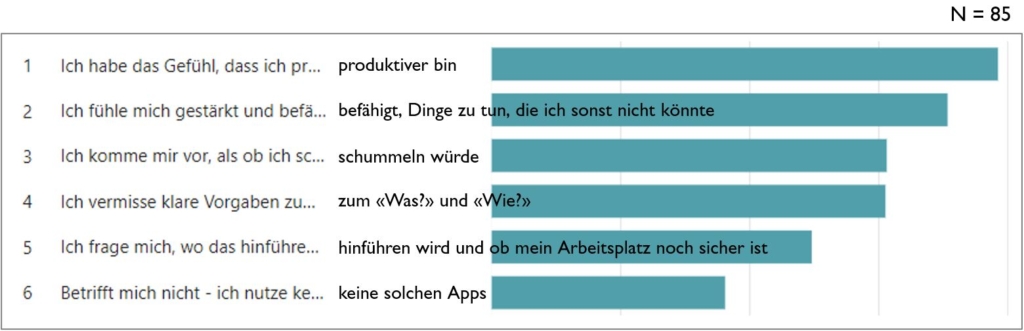
ChatGPT & Co sind auf dem Weg, zu ständig verfügbaren persönlichen Assistenzsystemen zu werden – sowohl im Arbeitsleben als auch darüber hinaus. Eine erfolgreiche Zusammenarbeit mit diesen Assistenzsystemen ist an Voraussetzungen gebunden. So müssen wir wissen, wie diese Systeme funktionieren, damit wir einschätzen können, wie wir sie für welche Aufgaben einsetzen können.
Für meine eigenen Bemühungen, diese Entwicklungen zu verstehen und die Folgen einschätzen zu können, habe ich in den letzten Monaten viele Ressourcen angeschaut – Blogposts, Kurzvideos, Studienberichte, etc. Drei Quellen, die ich besonders hilfreich finde, sind die folgenden:
- Stephen Wolframs Blogpost “What is ChatGPT Doing … and Why Does it Work?”
Stephen Wolfram ist Physiker, Informatiker und Mathematiker und hat unter anderem die Software Mathematica sowie die Suchmaschine Wolfram Alpha entwickelt. Sein ausführlicher Blogpost ist mittlerweile auch als Buch verfügbar. Sein Zugang ist sehr technisch und er erläutert sehr detailliert die Funktionsweisen von LLMs bzw. GPTs wie ChatGPT. Vieles davon verstehe ich nicht, manches, insbesondere manche Abbildungen, finde ich für mich hilfreich. - Die Unternehmensberatung McKinsey hat das Thema Generative KI im letzten Jahr in verschiedenen eigenen Untersuchungen und Berichten aufgegriffen. Dabei sind immer auch die Folgen für die Arbeits- und Geschäftswelt im Blick. Ein Jahr nach der Veröffentlichung von ChatGPT hat McKinsey Mitte November 2023 eine Sammlung von Artikeln zu generativer KI zusammengestellt: “12 must-reads for 12 months of gen AI breakthroughs”. Dabei sind sowohl Artikel, die die Technologie erläutern, als auch Artikel mit Ergebnissen aus Befragungen und Visualisierungen dazu. Für mich eine wichtige Quelle.
- Für die Forschungsförderung der gewerkschaftsnahen Hans Böckler-Stifung hat der Kulturwissenschaftler Michael Seemann eine Literaturstudie zu KI und LLMs erstellt, in der er ChatGPT erläutert und Folgen für die Arbeitswelt skizziert: “Künstliche Intelligenz, Large Language Models, ChatGPT und die Arbeitswelt der Zukunft”. Diese Studie ist sehr gut lesbar und bietet aus meiner Sicht eine gute Einführung in das Thema.

In diesem Post stelle ich für mich verschiedene Aussagen der Studie von Seemann zusammen. Es geht mir dabei nicht um Vollständigkeit, sondern um ein Festhalten von Punkten, die ich nicht aus dem Blick verlieren möchte.
In der Einleitung schreibt Seemann unter anderem:
Die Science Fiction, aber auch unsere kollektive Zukunftserwartung hatte viele Szenarien zu künstlicher Intelligenz auf dem Zettel. Aber dass KI aus-gerechnet im Kreativbereich so früh, so enorme Fortschritte machen würde, stand nicht auf der Liste. (…) Diese Zukunft ist nun aber da und bringt (…) unsere Vorstellungen von Arbeit durcheinander. Es ist gar nicht so lange her, dass sich Journalistinnen um die Zukunft der Kraftwagenfahrerinnen sorgten (…). Nun müssen sie um ihre eigenen Stellen bangen (…), während Kraftwagenfahrer*innen händeringend gesucht werden (…)
Kernpunkte
Seemann stellt seinem Bericht die folgenden Punkte als Zusammenfassung voran (Zitat):
- Large Language Models (LLMs) sind eine bahnbrechende, neue Technologie. Obwohl LLMs nur versuchen das jeweils nächste Wort eines Textes statistisch vorherzusagen, erlangen sie dadurch die Fähigkeit auf komplexe Konversationen zu reagieren, Anweisungen auszuführen, Denkaufgaben zu lösen und gut lesbare Texte zu schreiben. Noch sind sie für viele Zwecke ungeeignet und produzieren immer wieder Fehler, aber von einer rasanten Weiterentwicklung ist auszugehen.
- Die Frage, ob und was LLMs von dem, was sie ausgeben, „verstehen“ ist fachlich umstritten und leidet an unzureichenden Metriken und nicht gesicherten Indikatoren. (…)
- Studien über Arbeitsplatzverlust und Produktivitätsgewinne durch LLMs sind in der Frühphase und leiden an bereits oft kritisierten methodischen Mängeln und sollten trotz ihrer Empirie als weitgehend spekulativ angesehen werden. Gewinnbringender scheint, über Strukturveränderungen (…) nachzudenken (…)
- Der Einzug von LLMs in die Unternehmen wird die Machtverhältnisse in der Wirtschaft neu sortieren. (…)
- Der Einzug von LLMs in die Arbeitswelt wird auf zwei Wegen stattfinden: einerseits werden LLMs vom Management an verschiedenen Stellen zur Kostenreduktion eingesetzt werden. Zum anderen werden Mitarbeiter*innen bei ihrer täglichen Arbeit von sich aus auf LLMs – im Zweifel heimlich – zurückgreifen.
Seemann (2023): Künstliche Intelligenz… , S. 5.
- Der Einsatz von LLMs wird unterschiedliche Berufe auf drei verschiedene Arten treffen: Manche Berufe werden verschwinden, oder zumindest existenziell bedroht sein (Disruption). Andere Berufe werden durch LLMs nur im Randbereich tangiert (Integration). Einige Berufe werden nicht verschwinden, aber sich komplett neu erfinden müssen (Transformation).
Erläuterungen zu Begriffen und Modellen
Auf Begriffserläuterungen zu KI (Künstliche Intelligenz), NLP (Natural Language Processing), KNN (Künstliche Neuronale Netze, LLM (Large Language Models), GPT (Generative Pretrained Transformers), Tokens, Parameter und Kontext-Fenster folgen ein kurzer Abriss zur KI-Forschung sowie Erläuterungen zum Trainings-Prozess von LLMs und zu Transformer-Modellen.
Zu LLMs:
Am Ende dieses langen Prozesses [des Trainings eines Sprachmodells, CM] ist in den Embeddings [Vektoren, CM] die Komplexität von sprachlichen Äußerungen nicht nur auf Wort- oder Satzebene, sondern auch auf Konzept- und Ideen-Ebene gespeichert. Es entwickelt sich eine 1000-dimensionale Landkarte (bei GPT-3.5 sind es 12.288 Dimensionen) der Sprache. In dieser Landkarte ist hinterlegt, wie sich „Rot“ zu „Vorhang“ verhält, „Liebe“ zu „Haus“ und „Zitronensäurezyklus“ (…) semantisch ähnliche Wörter [liegen] nahe beieinander und semantisch unähnliche sind weiter entfernt.
Zu Transformer-Modellen:
„Der technologische Durchbruch, der die aktuell erfolgreichen generative KIs wie ChatGPT, aber auch Bildgeneratoren wie Midjourney (…) ermöglicht hat, wurde 2017 durch (…) Transformer-Modelle ermöglicht. Das ist eine Architektur für KNN [künstliche neuronale Netze, CM] , die jeder versteckten Ebene („Feed-Forward-Ebene“) eine sogenannte Aufmerksamkeits-Ebene zur Seite stellt (…). Die Aufmerksamkeits-Ebene assistiert der versteckten Ebene, indem sie den jeweiligen Kontext des zu bearbeitenden Tokens nach Relevanz sortiert und entsprechend gewichtet. Für jeden Token im Kontext-Fenster wird die Relevanz jedes anderen Tokens berechnet und diese in seinen Embeddings vermerkt.“ (S. 19)
Fähigkeiten von LLMs – zielgerichtet trainiert und emergent:
Die unstrittigen Fähigkeiten und Unzulänglichkeiten machen den Umgang mit LLMs zu einer nicht trivialen Navigationsaufgabe. Bevor man diese Systeme in irgendeinem Bereich zum Einsatz bringt, empfiehlt es sich nicht nur dringend, die Systeme und ihre Funktionsweise genau zu studieren, sondern auch, sich praktisch mit ihnen vertraut zu machen. Erst mit der Zeit entwickelt man ein Gespür dafür, was ein bestimmtes Modell leisten kann, wo seine Grenzen liegen und wo man sehr aufpassen muss, nicht auf den oft sehr selbstbewussten Ton des LLM hereinzufallen.
(…)
In verschiedenen Versuchsreihen beim Testen von LLMs fiel den Google-Forscherinnen auf, dass sich das Verhalten des Modells ab einer bestimmten Parameteranzahl sprunghaft änderte. So konnte das bestreffende Modell auf einmal sogenanntes „few-shot prompting“ (…) „Step-by-step reasoning“ (…) tauchte plötzlich einfach so auf, ohne, dass dem LLM diese Fähigkeit explizit beigebracht wurde. (…) Auch (…) das Kontextverständnis von Wörtern in Sätzen, arithmetische Aufgaben zu lösen oder sich in virtuellen Räumen zurechtfinden werden als emergente Fähigkeiten genannt. Alle diese Eigenschaften traten modell-übergreifend im Bereich zwischen 10^22 und 10^24 Parametern auf. Die Modelle scheinen den Forscherinnen zufolge ab dieser Größe eine Art Kipppunkt erreicht zu haben, der es ihnen ermöglicht, auf einer höheren Komplexitätsstufe Lösungen für Aufgaben zu finden.
Stochastische Papageien oder mehr?
Im Kontext der Diskussion um LLMs und GPTs wird immer wieder angeführt, sie würden Verständnis von Inhalten lediglich simulieren, da sie ja nur – basierend auf Wahrscheinlichkeitsrechnungen – nächste Tokens produzieren. In diesem Zusammenhang findet sich immer wieder auch die Charakterisierung dieser Modelle als “stochastische Papageien”. Und damit wird (bewusst oder unbewusst) unterstellt, dass man LLMs und GPTs und die darauf basierenden Anwendungen nicht ernst nehmen muss. Seemann stellt diese Sicht in Frage. Dafür zieht er (konkurrierende) sprachphilosophische Positionen heran.
Position 1
„Ohne tatsächlichen Zugang zur Welt kann ein hinreichend intelligentes System zwar Verständnis simulieren, aber wenn es darauf ankommt, zeigt sich doch, dass es zum echten Verständnis mehr als nur Mustererkennung in sprachlichen Äußerungen braucht. Es braucht den Rückverweis auf die Welt, auf die Dinge, auf die Realität.“
Position 2 (französische Sprachphilosophie – u.a. Barthes, Foucault, Derrida)
Worte gewinnen ihre Bedeutung nicht durch die Beziehung zur Welt, sondern durch ihre Beziehung zu anderen Worten. Dementsprechend gibt es auch keine Bedeutung im eigentlichen Sinne, kein „transzendentales Signifikat“, sondern Bedeutung ist nur ein Effekt der Zeichen und ihrer ständigen Weiterverweisung. (S. 37)
(…)
Man muss der Philosophie Derridas nicht in jeder Einzelheit folgen, um zu sehen, wie relevant diese Gedanken für das Verständnis der Funktionsweise von LLMs sind. Das Eingebundensein jedes Begriffes in ein System und das Spiel von Differenzen beschreibt den aus vieldimensionalen Embedding-Vektoren gebildeten latenten Raum von LLMs sehr treffend. Der ständige Aufschub von Bedeutung durch die Aktualisierung gegenwärtiger Sprachverwendung, lässt sich gut auf den Vorgang der Next-Word-Vorhersage anwenden. (S. 39)
(…)
Derridas Konzept von der Sprache bedeutet nicht, dass die Welt außerhalb der Sprache für das Denken irrelevant ist. Nur ist uns Menschen diese physische Welt immer nur symbolisch vermittelt zugänglich, also selbst wiederum als Text. Nach Derrida könnte man nun folgern, dass die Maschine tatsächlich nichts versteht von dem, was sie spricht. Damit hätte man seinerseits das Problem aber auch nur verschoben, denn dasselbe würde Derrida über uns Menschen sagen. Ihm ist „Verstehen“ ein per se suspektes Konzept. (…) Vermutlich brauchen wir für die Andersheit des „Verständnisses“, das LLMs zeigen, neue Begriffe. Wir müssten die überkommenen Semantiken menschlichen Verständnisses aufschnüren und ausdifferenzieren. Hannes Bajohr hat z. B. vorgeschlagen, die Bedeutungen, die LLMs erfassen, „dumme Bedeutung“ zu nennen (Bajohr 2023a). Er meint damit Bedeutungen, die ohne den Rückgriff auf Welterfahrung oder ein Bewusstsein gebildet werden. (S. 39-40)
Seemann nimmt zwar nicht eindeutig Stellung für die eine oder andere Position. Aber seine Schlussfolgerung signalisiert eine grössere Nähe zur Perspektive der französischen Sprachphilosophie: er ist sich nicht sicher, ob menschliche Weisen des Verstehens den maschinellen Weisen des Verstehens auf Dauer überlegen sein werden.
Auswirkungen auf die Arbeitswelt
In diesem Abschnitt spricht Seemann u.a. eine Reihe von verschiedenen Punkten an (S. 47-50):
- Konzentration des KI-Markets aufgrund der hohen Anforderungen an Ressourcen bei Entwicklung und Betrieb von Modellen;
- Auslagerung von Click-Working zur Optimierung der Modelle (RLHF) in Niedriglohn-Länder;
- Mögliche Stärkung einer Tendenz zu einer 2-Klassen-Gesellschaft:
„Da die generativen KIs zwar nicht gut genug sind, um menschliche Arbeit zu ersetzen, aber sich viele Leute menschliche Arbeit sowieso nicht leisten können, würden die sozial Schwachen zukünftig mit KIs abgespeist werden, während die, die es sich leisten können, sich weiterhin von Menschen bedienen, behandeln und beraten lassen (Hanna/Bender 2023).“
Meta-Effekte und Strukturveränderungen
Über die aus seiner Sicht nur wenig belastbare Studienlage zu Auswirkungen auf Berufsarbeit hinaus sind für Seemann insbesondere Strukturveränderungen wichtig. Hier führt er folgende Punkte an (S. 58-61):
- Urheberrechte und Marktmacht von Beschäftigtengruppen
„Die Befürchtung [der Writers Guild of America, CM] war aber nicht einfach, dass Hollywood sich seine Skripte von ChatGPT generieren lassen würde, sondern vielmehr, dass sich das Studio-Management von LLMs die Handlungsstruktur und das Basisskript generieren lassen und den angestellten Autorinnen dann nur noch die Überarbeitung bzw. Ausgestaltung der Details überlassen würden. Selbst wenn das LLM nur unbrauchbaren Quatsch liefern würde, verlören die Autorinnen das Urheberrecht an dem Drehbuch und man könnte sie mit einem Bruchteil des Geldes abspeisen (Broderick 2023).“ - Deskilling
„Automatisierung [führt] in der Realität oft dazu, dass bestimmte Arbeitsprozesse auch mit weniger Qualifizierung verrichtet werden (…). Dieses sogenannte „Deskilling“ führt dann zu einer höheren Austauschbarkeit der jeweiligen Arbeitenden und in Folge zu allgemeinen Lohneinbußen in dem Bereich.“ - Aufgefressene Produktivitätsgewinne?
„Während also die individuelle Produktivität durch LLMs steigen mag, wird sie vielleicht dadurch zunichte gemacht, dass alle Arbeitenden ihre Arbeitszeit dafür aufwenden müssen, sich gegen neue Formen von Spam, Phishing und Desinformationen zu wehren und sich durch immer ausufernden Informationsmüll zu wühlen.“ - Untergrabene Integrität von Kommunikation?
- Misstrauen von Lehrpersonen gegenüber den Ausarbeitungen von Lernenden / Studierenden;
- Secret Cyborg-Phänomen: „Much of the value of AI use comes from people not knowing you are using it.“ (Ethan Mollick);Automation Bias: “Studien weisen (…) darauf hin, dass Menschen computergestützte Vorschläge deutlich unkritischer akzeptieren und übernehmen, als es angemessen wäre.“
- Aufwand für Kommunikation ist immer auch ein Teil der Kommunikation. Z.B. persönlicher Brief / persönliche Email. Was passiert, wenn dieser Aufwand gegen Null tendiert? (S. 61)
Zukunftsszenarien zur Berufsarbeit
Seemann unterscheidet drei Szenarien für die Auswirkungen von generativer KI auf Berufsarbeit:
- Disruption: existenzielle Bedrohung von Berufsarbeit, beispielsweise für Beschäftigte in Call-Centern oder Übersetzer:innen;
- Integration: Nutzung der neuen Werkzeuge im Arbeisprozess, beispielsweise von medizinischem Personal, Pflegepersonal oder Immobilienmakler:innen;
- Transformation: radikale Veränderung der Berufsarbeit, beispielsweise bei Medienschaffenden, Lehrpersonen, in der Wissenschaft, in Beratungoder bei Mitarbeitenden in Verwaltungen.
Seemann skizziert diese drei Zukunftsszenarien anhand jeweils einer Berufsgruppe:
Disruption – Beispiel Übersetzer:innen
Seemann sieht hier eine Berufsgruppe in Auflösung. Maschinell erstellte Übersetzungen werden für einen grossen Teil der Übersetzungsaufgaben genutzt – für Gebrauchstexte und technische Dokumentationen ebenso wie für die meisten Bücher. Ausnahmen sind Kunst- und Literaturübersetzungen. Übersetzer:innen entwickeln sich in verschiedene neue Aufgabenprofile hinein:
- Lektorat – Überarbeitung bzw. Feinschliff von maschinell übersetzten Texten;
- Prompt-Übersetzungen;
- Beratung im Bereich KI-basierte Übersetzung, Qualitätssicherung und Modell-Training.
Integration – Beispiel Krankenpflege
Diesem Szenario zufolge bleibt der Kern der Berufsarbeit intakt und KI-basierte Werkzeuge werden in den Arbeitsprozess integriert. Beispiele sind Notizsysteme auf der Grundlage von gesprochener Sprache, die zeitglich zu manuell durchgeführten Arbeiten an Patient:innen geführt werden. Oder KI-basierte Systeme für eine personalisierte Zusammenstellung der Ernährung von Patient:innen. Oder Simultanübersetzungen, so dass auch Fachkräfte ohne gute Kenntnis der deutschen Sprache in der Pflege arbeiten können.
(…) die Arbeit am Körper ist weiterhin eine menschliche Arbeit, der Einsatz der Hände ist nicht nur eine Frage von mechanischer Kraft und feinmotorischer Sensibilität, sondern auch eine der Empathie, Zuwendung und des Mitgefühls: etwas, was die Maschinen nicht leisten können.
Transformation – Studierende, Lehrpersonen & Wissenschaftler:innen
In diesem Szenario skizziert Seeman u.a. Entwicklungen wie die folgenden (S. 69-74):
- starke Zunahme mündlicher Prüfungen gegenüber schriftlichen Prüfungsformen;
- Lernunterstützung durch personalisierte, omnikompetente maschinelle Tutoren;
- nur noch wenige Vorlesungen, dafür mehr betreute Kolloquien;
- “Publikations-Explosion” und Zusammenbruch des Peer-Review-Systems in der Wissenschaft;
- Transformation des Review-Prozesses für wissenschaftliche Arbeiten:
- alle eingereichten Publikationen werden in eine generische Standard-Sprache übersetzt und dabei auch anonymisiert;
- automatisierte / maschinelle Plausibilitätsprüfung;
- Review von kommentierten Zusammenstellungen zu Bündeln von Publikationen durch menschliche Reviewer;
- Überprüfung von Beobachtungen / Überlegungen mit Unterstützung von LLMs;
- Bestätigung der Bewertung der Original-Einreichung durch die Peer-Reviewer.
Seemann, Michael (2023): Künstliche Intelligenz, Large Language Models, ChatGPT und die Arbeitswelt der Zukunft. Working Paper Forschungsförderung, Nr. 304, September 2023. Düsseldorf: Hans-Böckler-Stiftung.