Im Zuge der fortschreitenden Digitalisierung und Automatisierung ergeben sich auch neue Möglichkeiten der Produktion von medialen Inhalte bzw. Lernressourcen. Für Bildungsverantwortliche und Inhalte-Entwickler ist es ratsam, diese Entwicklungen im Blick zu behalten.
Automatisierte Zusammenstellungen von Lernressourcen sind nicht neu. Aktuell im Markt verfügbare Plattformen wie beispielsweise EdCast, Degreed oder FuseUniversal erlauben es, spezifisch auf ein Nutzer-Profil (Funktion, Aufgaben, Weiterbildungshistorie) zugeschnittene Lerninhalte anzuzeigen:
Ein nächster Entwicklungsschritt ist die (teil-)automatisierte Produktion von Lernressourcen aus vorhandenen Materialien. Auch hierzu gibt es erste Produkte und verschiedene laufende Projekte:
Automatisierte Produktion von Wissenstests
Volley.com bietet eine Lösung, um für sich rasch änderne Wissensgebiete (z.B. Cybersecurity) Text-Zusammenfassungen und Wissens-Tests zu erstellen. Dazu müssen zunächst Dokumente (z.B. technische Beschreibungen zu den neuesten Phishing-Angriffen) in ein System eingelesen werden, in dem diese dann semantisch analysiert werden. Aufbauend auf der inhaltlichen Analyse der Dokumente können dann automatisch kurze Wissenstests zu den eingelesenen Inhalten erzeugt werden.

Mehr dazu in diesem (Werbe-)Video von volley.com.
Automatisierte Anreicherung von Webseiten mit passenden Inhalten
Anyclip.com bietet mit “LuminousX” eine Plattform, über die für eine beliebige Webseite passende Inhalte ergänzt werden können. Ein Beispiel bietet diese Seite von Venturebeat.com, auf der – ergänzend zu einem Artikel über KI-unterstützte Video-Produktion bei einem MOOC-Anbieter – automatisch weitere thematisch verwandte Videos aus dem Bereich Bildung, Ed-Tech, etc. vorgeschlagen werden.
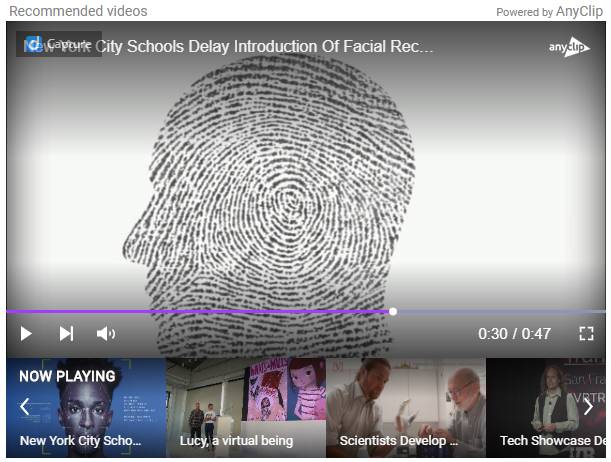
Auch wenn diese Lösung ursprünglich aus dem Bereich des Web- und Inhalte-Marketings kommt, so ist ein Einsatz auch im Bildungsbereich denkbar.
Automatisiertes Erzeugen von Zusammenfassungen und Büchern
Technische Lösungen, die Texte automatisch zusammenfassen, finden sich schon seit einigen Jahren im WWW (z.B. autosummarizer.com oder resoomer.com). Eine Übersicht zu Nutzungsszenarien von Autosummarizer-Applikationen im Unternehmenskontext bietet dieser Blogpost.
Der Wissenschaftsverlag Springer hat kürzlich in Zusammenarbeit mit Wissenschaftlern der Goethe Universität Frankfurt das erste von einem Computer / Algorithmus zusammengestellte Buch publiziert. Dieses Buch enthält automatisch erstellte Zusammenfassungen der neuesten Forschungsliteratur über Lithium-Ionen-Batterien. Ein Forschungsgebiet, dass mit mehr als 53’000 Publikationen in den letzten drei Jahren sehr dynamisch ist und kaum noch “manuell” gesichtet werden kann.

Hier ein kurzer Ausschnitt aus dem Inhaltsverzeichnis:

In einer Sendung des Deutschlandfunks wird dieses Projekt näher erläutert. Hier nur ein kurzer Auszug daraus:
“Das Verfahren besteht aus zwei Stufen. In der ersten Stufe wird quasi das Inhaltsverzeichnis generiert oder die Dokumentenstruktur, in der zweiten Stufe wird der Text ergänzt. Die Generierung der Dokumentenstruktur erfolgt im Wesentlichen auf Basis eines sogenannten Clustering-Verfahrens. Das heißt, wir nehmen alle Publikationen in unsere Domäne, ermitteln deren jeweilige Ähnlichkeit miteinander und gruppieren dann die ähnlichen Publikationen zueinander. Dann kommt der Nutzer ins Spiel und der sagt: Wie viele Kapitel möchte ich haben, innerhalb jedes Kapitels wie viele Sektionen? Und dann bilden wir mit Standardverfahren aus dem Clustering eben genau eine Gruppierung in, sagen wir mal, fünf potenzielle Kapitel mit jeweils fünf potenziellen Subsektionen. Innerhalb dieser Subsektionen nun sind die Publikationen einander unterschiedlich ähnlich, und wir können diejenigen, die sich quasi im Mittelpunkt eines Clusters befinden, als die prototypischsten behandeln.”
Quelle: Deutschlandfunk
Ergänzend hierzu eine schematische Darstellung des Herstellungsprozesses aus dem einleitenden Kapitel des Buches.
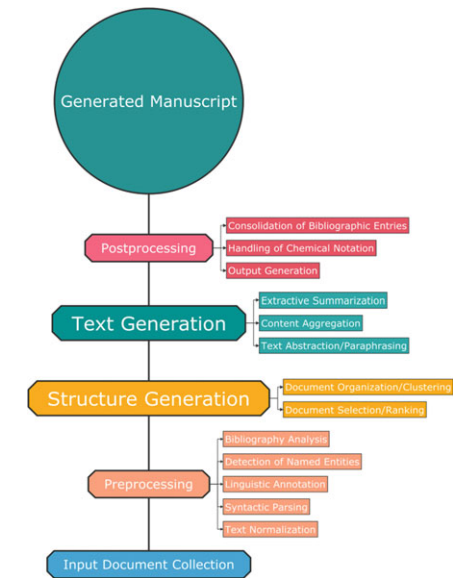
In diesem Kapitel werden auch die aktuell noch bestehenden Herausforderungen aufgeführt, an den weiter gearbeitet wird, beispielsweise Verbesserungen bei Satzkonstruktionen, bei kontextsensitiven Umschreibungen oder bei aussagekräftigen Überschriften.
Solche automatisch erstellten Übersichtspublikationen sind nicht nur für (Nachwuchs-)Wissenschaftler relevant, die sich in ein neues Themengebiet einarbeiten müssen. Die gleiche Problemstellung ergibt sich ja in ganz vielen weiteren (Arbeits-)Kontexten.
Automatisiertes Erzeugen von Vorlesungs-Videos
Vorlesungs-Videos sind ein zentrales Element vieler MOOCs. Die Produktion dieser Videos ist aufwändig. Es braucht ein Studio und Ausrüstung (Kamera, Ton, Licht, etc.), der oder die Fachexpertin muss ins Studio kommen, es braucht eine Regie, später muss die Aufzeichnung zusammengeschnitten werden, etc. Und wenn dann die Inhalte aktualisiert werden müssen, geht die ganze Übung wieder von vorne los.
Kein Wunder also, dass es Bemühungen gibt, diesen Prozess zu vereinfachen. Alltagstaugliche Lösungen gibt es noch nicht, aber es wird daran gearbeitet.
Aus dem AI-Team von Udacity, einem MOOC-Anbieter, ist ein Prototyp einer Lösung hervorgegangen: LumièreNet. Diese Lösung basiert ausschliesslich auf neuronalen Netzen, die darauf trainiert wurden, aus den bereits verfügbaren Videosequenzen einer Person (z.B. einer Lehrperson) und später aufgenommenen Sprachaufzeichnungen (z.B. aktualisierte Sequenz zu einer Vorlesung) ein Video mit einem neuen Inhalt zu erstellen:
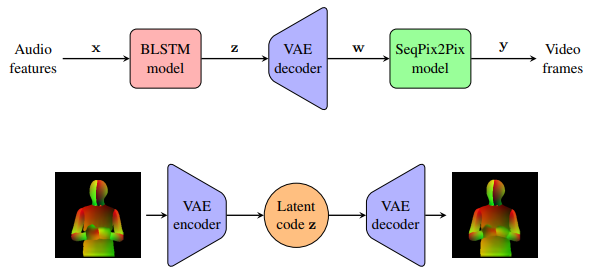
Hier ein Beispiel für ein auf diese Weise erzeugtes Video.

Wie gesagt: noch nicht überzeugend, aber die Ergebnisse werden vermutlich bald besser sein.
Verweise:
Kim / Ganapathi (2019): LumièreNet: Lecture Video Synthesis from Audio.
Schreiben Sie einen Kommentar