Individualisierung bzw. Personalisierung ist ein wichtiger Erfolgsfaktor für die Wirksamkeit von Lern- und Entwicklungsprozessen. Dies hat Leonard Bloom schon vor mehr als 30 Jahren anhand von empirischen Daten aufgezeigt (vgl. dazu den Einstieg in diesen Blogbeitrag).
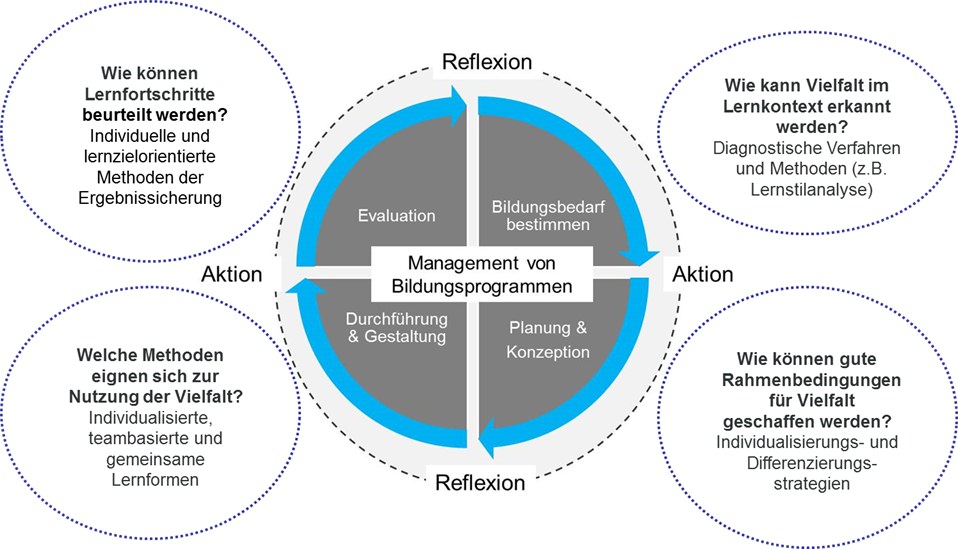
Vor dem Hintergrund zunehmender Diversität von Mitarbeitenden (Bildungsbiografie, kultureller Hintergrund, globalisierte Unternehmungen bzw. Wertschöpfungsnetzwerke) steigen die Anforderungen an den Umgang mit dieser Diversität im Rahmen von Lern- und Entwicklungsprozessen. Ein Ansatz ist hier natürlich, die Mitarbeitenden bzw. Lernenden stärker in die Verantwortung zu nehmen und ihnen die Möglichkeit zu geben, ihre (informellen) Lernaktivitäten selbst zu bestimmen. Der Umgang mit Diversität ist aber auch in allen Schritten eines eher formalen Bildungsprozesses wichtig: von der Bestimmung des Entwicklungsbedarfs über die Planung und Konzeption sowie die methodische Durchführung von Lernprozessen bis hin zur deren Evaluation (vgl. die folgende Abbildung).
Diese Woche fand der Online Summit der eLearning Guild zum Thema «Learning Personalization» statt – wie gewohnt, zwei halbe Tage mit jeweils vier Fachbeiträgen im virtuellen Kursraum. Alle Beiträge stellten die Möglichkeiten und Herausforderungen einer datengetriebenen Personalisierung von Lernprozessen in den Mittelpunkt.
Als Orientierungspunkt für die Beiträge dienten dabei zwei Definitionen von «Personalisierung» im Zusammenhang mit Lernaktivitäten:
Personalized learning provides instruction tailored to an individual based on the learner’s interests, experience, preferred learning methods, learning pace, job role, or other factors. (ATD / i4cp)
Personalized learning is using everything we know about you to provide the right support at the right time. (JD Dillon & Megan Torrance)
So zeigte beispielsweise Megan Torrance (Torrancelearning) in ihrem Beitrag «How (your) data can enable learning personalization (today)» auf, welche Daten heute häufig schon zur Verfügung stehen (z.B. über HR-Systeme), um Lernangebote zu personalisieren:
- Bevorzugte Sprache
- Bevorzugtes Endgerät (z.B. Tablet)
- Funktion / Rolle in der Organisation
- Organisationseinheit
- Anstellungsverhältnis (Teil- / Vollzeit)
- Beschäftigungsdauer im Unternehmen
- Wohnort & Zeitzone
Ergänzt werden können diese Daten durch Informationen aus Lern- und Produktivsystemen:
- Weiterbildungshistorie (z.B. Teilnahme an Programmen)
- Aktueller Bearbeitungsstand (z.B. in einem Online-Kurs)
- Bereits aufgerufene Inhalte (z.B. einer Inhalte-Bibliothek)
- Häufig durchgeführte Transaktionen (z.B. an einer Maschine oder in einem ERP-System)
Eine verbreitete Herausforderung besteht allerdings darin, dass diese Informationen in unterschiedlichen Systemen gehalten und zunächst einmal bereinigt und konsolidiert werden müssen. Viele aktuell im Einsatz befindliche Lern-Management-Systeme unterstützten dabei nur eine Filterung bzw. Zuordnung von Inhalten auf der Grundlage dieser und ähnlicher Informationen.
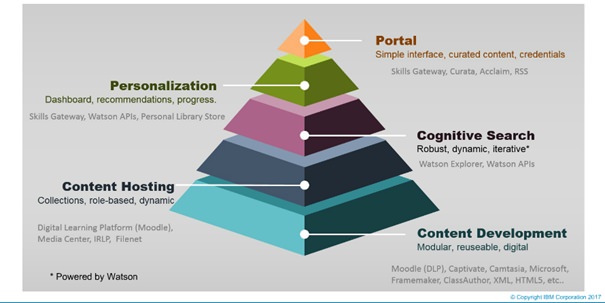
Teri Austin und Meg Peterson von IBM stellten in ihrem Beitrag die personalisierte Lernumgebung «IBM Skills Gateway» für Mitarbeitende und Partner von IBM vor. Sie betonten dabei, dass die Bearbeitung des Themas «Personalisierung» nicht erst bei der Filterung von Inhalten beginnen darf, sondern schon in die Erstellung der Inhalte einfliessen muss. Die Architektur von «IBM Skills Gateway» besteht demzufolge aus mehreren Komponenten bzw. Schichten:
- Inhalte-Entwicklung (digital, modular, maschinell lesbar);
- Inhalte-Hosting bzw. –Bereitstellung (z.B. rollenbasiert oder in dynamisch sich verändernden Sammlungen);
- Kognitive Suche (IBM Watson);
- Personalisierung (u.a. über ein persönliches Dashboard, über Empfehlungen oder auf der Grundlage von eigenen Lernfortschritten);
- Portalseite mit einfacher Benutzeroberfläche.
Diese Lernplattform ist übrigens öffentlich zugänglich. Man kann sich dort registrieren und dann die Inhalte und den Aufbau bzw. die Funktionsweise der Lernplattform erkunden. Die öffentlich verfügbaren Inhalte sind allerdings (noch) sehr beschränkt.
In seinem Beitrag «What technologies are enabling learning personalization» hat Nick Floro (Sealworks) in einem Turbo-Tempo eine umfangreiche Sammlung von Werkzeugen vorgestellt. Das war für meinen Geschmack zu Tech-lastig und mir hat auch die Systematik gefehlt. Mitgenommen habe ich u.a. Hinweise zu
- Amazon Lex (ein Webservice, über den man sich selbst Chatbots bauen kann – vgl. die folgende Abbildung),

- Amazon Machine Learning
«Amazon Machine Learning ist ein Service, mit dem Entwickler aller Wissensstufen die Technologie für machinelles Lernen problemlos nutzen können. Amazon Machine Learning bietet Visualisierungstools und Assistenten, die Sie durch den Aufbauprozess für Machine Learning-Modelle (ML) begleiten, ohne dass Sie komplexe ML-Algorithmen und ‑Technologien erlernen müssen. Wenn Ihre Modelle fertig sind, können Sie bei Amazon Machine Learning mithilfe einfacher APIs Prognosen für Ihre Anwendung abrufen, ohne benutzerdefinierte Prognosecodes implementieren oder Infrastrukturen verwalten zu müssen.» (Link)
Anschlussfähiger fand ich dagegen den Beitrag von JD Dillon (Axonify) mit dem Titel «Adaptive learning: The next phase of digital enablement». Dillon warb für die Weiterentwicklung von «digital learning» (Lernen mit digitalen Medien) zu adaptivem Lernen im Sinne eines «continuous digital enablement» (also einer kontinuierlichen Befähigung auf der Basis digitaler Werkzeuge).
Für diese Befähigung sind vier Aspekte zentral:
- Daten
Es braucht Daten
– zu demografischen Merkmalen der Lernenden,
– zu deren Lernaktivitäten,
– zu ihrem aktuellen Wissensstand,
– zu aktuellen Arbeitsaufgaben und
– zum Leistungsstand bezüglich dieser Aufgaben. - Inhalte
Es braucht
– kleine Inhalte-Einheiten (‘microlearning’) und
– unterschiedliche Typen von Inhalten. - Technologie
Es braucht
– Algorithmen, die die Personalisierung der Lernaktivitäten ermöglichen,
– Verfahren der Datensammlung und Datenauswertung sowie
– Schnittstellen zwischen den verschiedenen Systemen, in denen (Prozess-)Daten anfallen bzw. vorliegen. - Menschen
Es braucht Menschen,
– die neugierig und entwicklungsorientiert sind,
– die Verantwortung für ihre Leistung übernehmen und
– die verstehen, wie adaptive Lernumgebungen funktionieren und wie sie Vorschläge und Empfehlungen einzuordnen haben.
Dillon betonte in seinem Beitrag mehrfach, wie wichtig es ist, dass die Möglichkeiten einer datengetriebenen Personalisierung von den Lernenden / Mitarbeitenden akzeptiert werden. Es dürfe nicht sein, dass Mitarbeitende sich in einer unguten Weise beobachtet fühlten und sich wunderten, woher «das System» denn nun schon wieder dieses oder jenes über sie wisse. Der Bezug zu einer gewünschen Leistungsunterstützung müsse jederzeit unmittelbar und klar sein.
Nachtrag 12.11.2017
Jochen Robes hat im Weiterbildungsblog auf einen Special Report zum Thema “Personalized Learning” im Online Magazin Education Week aufmerksam gemacht. Dort wird in verschiedenen Beiträgen durchaus kontrovers über den Sinn oder Unsinn einer durch digitale Medien und Werkzeuge unterstützten Personalisierung von Lernen diskutiert.
[…] Learning Personalization (November 2017) […]